
Java常量池
Java常量池介绍
java中的常量池技术,是为了方便快捷地创建某些对象而出现的,当需要一个对象时,就可以从池中取一个出来(如果池中没有则创建一个),则在需要重复创建相等变量时节省了很多时间。常量池其实也就是一个内存空间,不同于使用new关键字创建的对象所在的堆空间。String类也是java中用得多的类,同样为了创建String对象的方便,也实现了常量池的技术。
常量池中对象和堆中的对象
-
public class Test{
-
Integer i1=new Integer(1);
-
Integer i2=new Integer(1);
-
//i1,i2分别位于堆中不同的内存空间
-
System.out.println(i1==i2);//输出false
-
Integer i3=1;
-
Integer i4=1;
-
//i3,i4指向常量池中同一个内存空间
-
System.out.println(i3==i4);//输出true
-
//很显然,i1,i3位于不同的内存空间
-
System.out.println(i1==i3);//输出false
-
}
8种基本类型的包装类和对象池
java中基本类型的包装类的大部分都实现了常量池技术,这些类是Byte,Short,Integer,Long,Character,Boolean,另外两种浮点数类型的包装类则没有实现。另外Byte,Short,Integer,Long,Character这5种整型的包装类也只是在对应值小于等于127时才可使用对象池,也即对象不负责创建和管理大于127的这些类的对象。以下是一些对应的测试代码:
- public class Test{
- public static void main(String[] args){
- //5种整形的包装类Byte,Short,Integer,Long,Character的对象,
- //在值小于127时可以使用常量池
- Integer i1=127;
- Integer i2=127;
- System.out.println(i1==i2)//输出true
- //值大于127时,不会从常量池中取对象
- Integer i3=128;
- Integer i4=128;
- System.out.println(i3==i4)//输出false
- //Boolean类也实现了常量池技术
- Boolean bool1=true;
- Boolean bool2=true;
- System.out.println(bool1==bool2);//输出true
- //浮点类型的包装类没有实现常量池技术
- Double d1=1.0;
- Double d2=1.0;
- System.out.println(d1==d2)//输出false
- }
- }
String也实现了常量池技术
String类也是java中用得多的类,同样为了创建String对象的方便,也实现了常量池的技术,测试代码如下:
- public class Test{
- public static void main(String[] args){
- //s1,s2分别位于堆中不同空间
- String s1=new String("hello");
- String s2=new String("hello");
- System.out.println(s1==s2)//输出false
- //s3,s4位于池中同一空间
- String s3="hello";
- String s4="hello";
- System.out.println(s3==s4);//输出true
- }
- }
例子
接下来我们引用一些网络上流行的常量池例子,然后借以讲解。 1 String s1 = "Hello";
2 String s2 = "Hello";
3 String s3 = "Hel" + "lo";
4 String s4 = "Hel" + new String("lo");
5 String s5 = new String("Hello");
6 String s6 = s5.intern();
7 String s7 = "H";
8 String s8 = "ello";
9 String s9 = s7 + s8;
10
11 System.out.println(s1 == s2); // true
12 System.out.println(s1 == s3); // true
13 System.out.println(s1 == s4); // false
14 System.out.println(s1 == s9); // false
15 System.out.println(s4 == s5); // false
16 System.out.println(s1 == s6); // true
首先说明一点,在java 中,直接使用==操作符,比较的是两个字符串的引用地址,并不是比较内容,比较内容请用String.equals()。
s1 == s2这个非常好理解,s1、s2在赋值时,均使用的字符串字面量,说白话点,就是直接把字符串写死,在编译期间,这种字面量会直接放入class文件的常量池中,从而实现复用,载入运行时常量池后,s1、s2指向的是同一个内存地址,所以相等。
s1 == s3这个地方有个坑,s3虽然是动态拼接出来的字符串,但是所有参与拼接的部分都是已知的字面量,在编译期间,这种拼接会被优化,编译器直接帮你拼好,因此String s3 = "Hel" + "lo";在class文件中被优化成String s3 = "Hello";,所以s1 == s3成立。
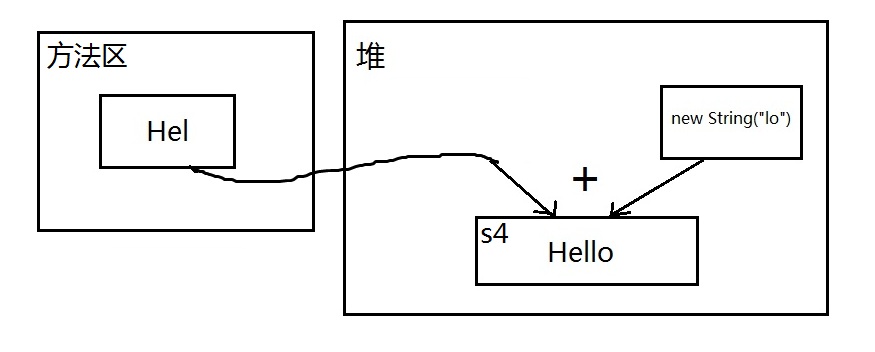
s1 == s4当然不相等,s4虽然也是拼接出来的,但new String("lo")这部分不是已知字面量,是一个不可预料的部分,编译器不会优化,必须等到运行时才可以确定结果,结合字符串不变定理,鬼知道s4被分配到哪去了,所以地址肯定不同。配上一张简图理清思路:
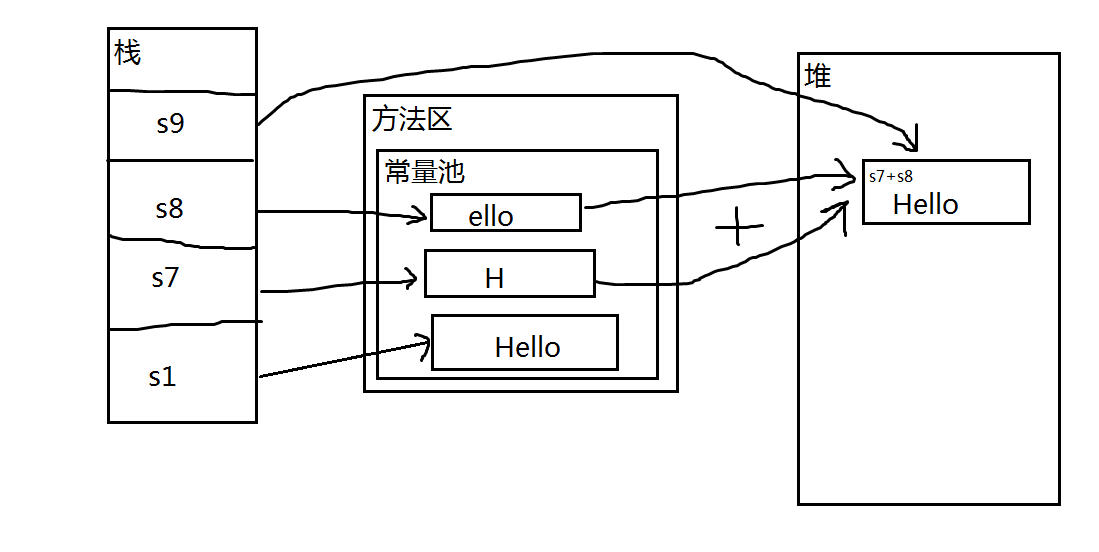
 s1 == s9也不相等,道理差不多,虽然s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟是编译器,不可能当解释器用,所以不做优化,等到运行时,s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。
s1 == s9也不相等,道理差不多,虽然s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟是编译器,不可能当解释器用,所以不做优化,等到运行时,s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。
s4 == s5已经不用解释了,绝对不相等,二者都在堆中,但地址不同。
s1 == s6这两个相等完全归功于intern方法,s5在堆中,内容为Hello ,intern方法会尝试将Hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了Hello字符串,所以intern方法直接返回地址;而s1在编译期就已经指向常量池了,因此s1和s6指向同一地址,相等。
版权声明:本文为JAVASCHOOL原创文章,未经本站允许不得转载。